4
Basics
K-nearest Neighbors
Theory
K-Nearest Neighbors (KNN) is a simple, instance-based learning algorithm used for both classification and regression. It makes predictions based on the k closest training examples in the feature space. KNN is non-parametric and stores all training data, making predictions at query time.
Visualization
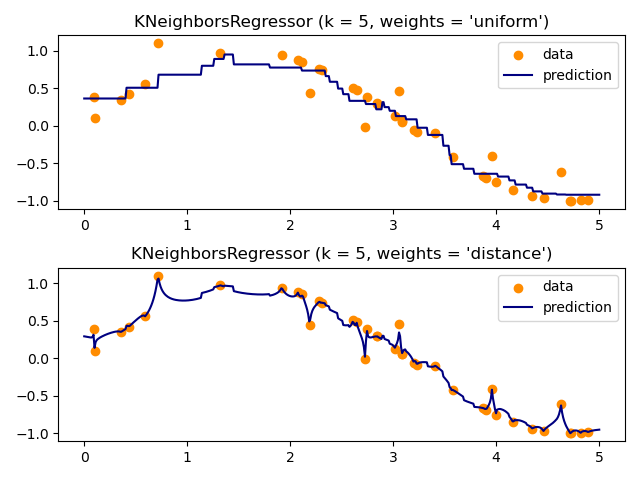
Mathematical Formulation
Distance Metric (Euclidean): d(x, x') = √(Σ(xᵢ - x'ᵢ)²) Classification: Majority vote among k neighbors Regression: Average of k neighbor values
Code Example
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# Generate dataset
X, y = make_classification(n_samples=200, n_features=2,
n_redundant=0, n_informative=2,
random_state=42)
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Train KNN
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# Evaluate
train_score = knn.score(X_train, y_train)
test_score = knn.score(X_test, y_test)
print(f"Training Accuracy: {train_score:.3f}")
print(f"Test Accuracy: {test_score:.3f}")