21
Recommender Systems
Content-based Recommendation Systems
Theory
Content-based filtering recommends items similar to those a user liked in the past, based on item features rather than other users' behavior. It builds a profile for each user based on features of items they've interacted with.
Visualization
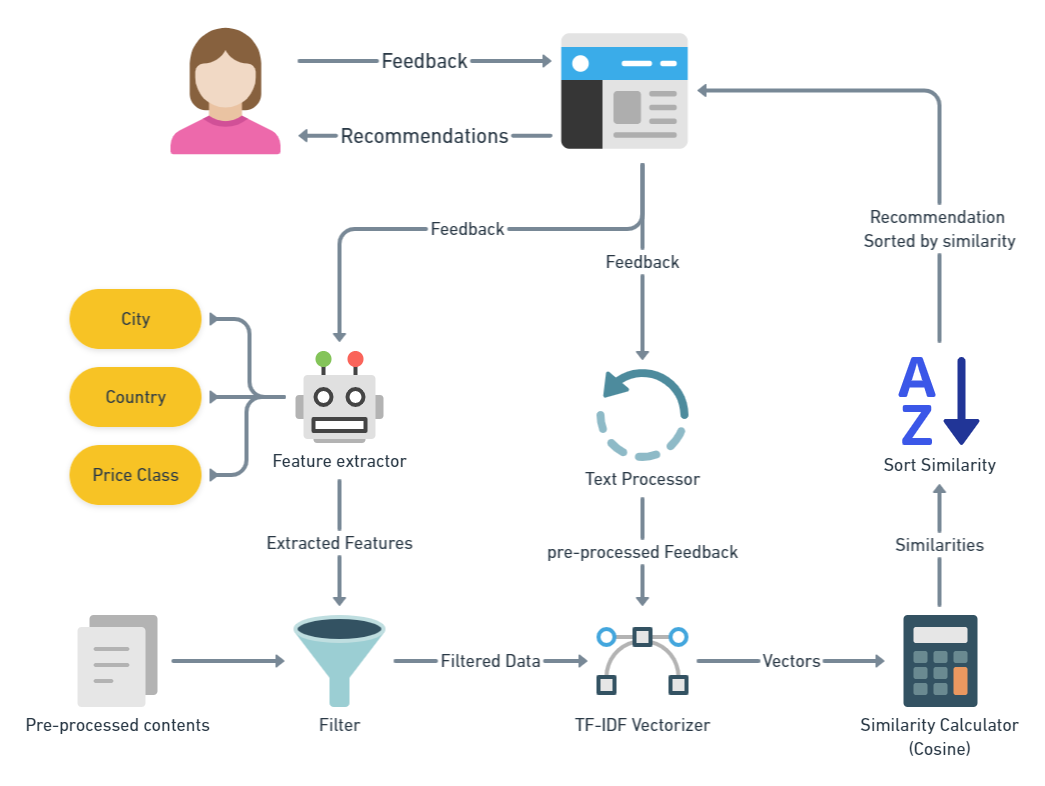
Mathematical Formulation
Algorithm: 1. Extract features from items (TF-IDF, attributes) 2. Build user profile from liked items 3. Calculate similarity (cosine, Euclidean) 4. Recommend top-k similar items Cosine Similarity: cos(θ) = (A·B) / (||A|| ||B||)
Code Example
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
# Sample movie dataset
movies = pd.DataFrame({
'movie_id': [1, 2, 3, 4, 5],
'title': ['The Matrix', 'Inception', 'The Notebook',
'Interstellar', 'Titanic'],
'genre': ['Sci-Fi Action', 'Sci-Fi Thriller',
'Romance Drama', 'Sci-Fi Drama', 'Romance Drama']
})
# Create TF-IDF features
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(movies['genre'])
# User liked movies 1 and 2
user_profile = tfidf_matrix[[0, 1]].mean(axis=0)
# Calculate similarities
similarities = cosine_similarity(user_profile, tfidf_matrix).flatten()
# Get recommendations
movies['similarity'] = similarities
recommendations = movies[~movies['movie_id'].isin([1, 2])]\
.nlargest(2, 'similarity')
print("Recommendations:")
print(recommendations[['title', 'genre', 'similarity']])